Understanding Digital Audio: Sampling, Quantization, and More

Quantization and sampling are ways to take an analog signal with variable voltage and translate it into digital data.
In the digital age, audio is omnipresent in our daily lives, from music streaming to podcasts and beyond. Understanding digital audio formats is crucial for anyone producing, distributing, or enjoying audio content. This blog delves into the intricacies of digital audio formats, their technical aspects, and their practical applications in recording and distribution.
How Digital Audio Works
Understanding the processes of quantization and sampling is essential for comprehending how digital audio works. These processes convert continuous analog signals into discrete digital values that digital systems can store and manipulate.
Sampling
Definition: Sampling converts a continuous analog audio signal into discrete digital values by measuring the signal's frequency and amplitude at regular intervals. These intervals are known as sample points, and the rate at which these measurements are taken is called the sample rate, measured in Hertz (Hz).

The sample rate of this signal would be 19Hz and as that is the x axis. The bit depth would be 16 bit as that is the y axis. So the sampling rate would be 19Hz at 16 bit.
How It Works:
Analog Signal: The continuous audio signal is picked up by a microphone or another input device.
Sample Points: At regular intervals, the amplitude and frequency of the audio signal is measured. These measurements are called samples.
Sample Rate: The number of samples taken per second determines the sample rate. For example, a sample rate of 44.1 kHz means 44,100 samples are taken every second.
Bit Depth: The number of samples taken per second of the amplitude depth of the cross-section. For example, we measure this in 16-bit, 24, or 32-bit depths.
Sampling effectively captures the time-based and amplitude variations in the audio signal, converting it into discrete points representing the waveform.
Common Sample Rates
44.1 kHz (CD Quality):
Description: The standard sample rate for audio CDs, 44.1 kHz captures 44,100 samples per second.
Use Case: Widely used in consumer audio formats such as CDs and most streaming services.
Benefits: This rate is sufficient to capture the full range of human hearing (20 Hz to 20 kHz), ensuring accurate reproduction of audio without requiring excessive storage space.
48 kHz:
Description: A common sample rate in professional audio and video production, 48 kHz captures 48,000 samples per second.
Use Case: Standard in video production, television, and professional audio environments.
Benefits: Offers slightly better high-frequency capture compared to 44.1 kHz and is the industry standard for synchronizing audio with video.
88.2 kHz:
Description: A high-resolution sample rate that captures 88,200 samples per second.
Use Case: Used in high-fidelity recording and mastering, especially when the final product will be downsampled to 44.1 kHz (e.g., CD production).
Benefits: Provides an excellent balance between capturing high-frequency detail and ease of downsampling to 44.1 kHz, reducing potential aliasing artifacts.
96 kHz:
Description: A high-resolution sample rate, 96 kHz captures 96,000 samples per second.
Use Case: Commonly used in professional music production, film scoring, and other high-resolution audio applications.
Benefits: Captures more detail and high-frequency content than 44.1 kHz or 48 kHz, making it ideal for recordings that require extreme fidelity. However, it demands more storage and processing power.
192 kHz:
Description: One of the highest commonly used sample rates, capturing 192,000 samples per second.
Use Case: Used in ultra-high-resolution audio applications, archival work, and situations where maximum fidelity is required.
Benefits: Provides incredibly detailed audio reproduction, capturing the finest nuances of a performance. However, it results in significantly larger file sizes and may be overkill for most practical listening environments.
Common Bit Depths
16-bit:
Description: The standard bit depth for CDs, 16-bit audio allows for 65,536 possible amplitude values per sample (2^16).
Use Case: Commonly used in consumer audio formats like CDs.
Benefits: Provides a good balance between audio quality and file size. While it captures a decent dynamic range, it's more susceptible to quantization noise compared to higher bit depths.
24-bit:
Description: Frequently used in professional recording studios, 24-bit audio allows for 16,777,216 possible amplitude values per sample (2^24).
Use Case: Standard in professional audio recording, mixing, and mastering.
Benefits: Offers greater dynamic range (the difference between the quietest and loudest parts of the audio) and lower noise levels, resulting in cleaner, more detailed sound.
32-bit:
Description: 32-bit audio allows for 4,294,967,296 possible amplitude values per sample (2^32).
Use Case: Used in some high-end audio processing and in environments where extremely high dynamic range is required.
Benefits: Provides an even higher dynamic range than 24-bit, although the benefits in practical listening scenarios are minimal because human hearing is typically not sensitive enough to perceive the improvements beyond 24-bit. However, it can be useful in recording environments where extreme levels of gain might be applied.
32-bit Float:
Description: Unlike integer-based bit depths, 32-bit float uses floating-point arithmetic, which provides an effectively infinite dynamic range. This format stores data in a way that allows for extremely precise representation of very quiet and very loud sounds, without the risk of clipping.
Use Case: Common in high-end audio production and scientific applications where precision is crucial. It's particularly useful during recording and processing, as it can prevent data clipping and distortion during gain adjustments.
Benefits: The floating-point format drastically reduces the risk of distortion and clipping during processing, making it ideal for recording environments where significant dynamic range adjustments may occur.
Why Higher Bit Depths Matter
Higher bit depths enhance audio quality by:
Increasing Dynamic Range: A higher bit depth means that the audio signal can represent a greater range of amplitudes, capturing more subtle differences between the quietest and loudest parts of the audio.
Reducing Quantization Noise: With more possible amplitude values, the difference between the actual analog signal and the quantized digital signal is minimized, resulting in lower quantization noise and a clearer, more accurate reproduction of the original sound.
Quantization
Definition: Quantization is the process of converting the continuous range of amplitude values in an analog signal into a finite set of discrete digital values during analog-to-digital conversion. This is necessary because digital systems can only store data in discrete steps. The quantization precision is determined by the bit depth, which specifies the number of possible discrete values each sample can take.
How It Works:
Sample Amplitude: After sampling the continuous analog signal, each sample has an amplitude within a specific range. These amplitudes are typically continuous values.
Discrete Levels: Quantization maps these continuous amplitude values to the nearest value within a finite set of levels. The bit depth determines the number of these levels. For example, a 16-bit depth allows for 65,536 possible discrete levels (2^16).
Quantization Noise: This process introduces a small error known as quantization noise, which arises because the exact value of the original analog signal is approximated to the nearest available digital value. The larger the bit depth, the smaller the quantization noise, as the signal is represented more accurately.
Purpose: Quantization captures the amplitude variations in the audio signal, translating the continuous analog signal into a digital format that can be stored and processed by digital systems. The greater the bit depth, the more accurately the analog signal is represented in the digital domain, which results in better sound quality.
Key Differences Between Sampling and Quantization
Purpose:
Sampling: Captures the time-based characteristics of the audio signal by taking periodic measurements of the signal’s amplitude at specific intervals. This process transforms a continuous analog signal into a series of discrete time points.
Quantization: Converts the continuous amplitude values obtained during sampling into a finite set of discrete digital values. This step is essential for storing and processing the sampled data in a digital system.
Process:
Sampling: Determines how frequently the signal is measured, which is controlled by the sample rate (e.g., 44.1 kHz, 48 kHz). The sample rate defines the temporal resolution of the digital representation, with higher rates capturing more detail in the time domain.
Quantization: Determines the precision with which each amplitude measurement is represented, dictated by the bit depth (e.g., 16-bit, 24-bit). The bit depth defines the number of possible discrete amplitude levels, affecting the dynamic range and the accuracy of the digital representation.
Outcome:
Sampling: Produces a series of discrete time points, each representing the amplitude of the audio signal at a specific moment in time. This sequence of samples forms a digital approximation of the original analog waveform.
Quantization: Produces a series of discrete amplitude values corresponding to each sampled time point. These quantized values are then stored as digital data, ready for further processing, storage, or playback. Quantization inherently introduces some level of error, known as quantization noise, due to the approximation of the continuous signal.
Dithering and Its Role in Digital Audio
Dithering is a technique used in digital audio to minimize the distortion caused by quantization noise. When an analog signal is converted into a digital format, the process of quantization introduces small errors known as quantization noise. Dithering helps to mask this noise by adding a small amount of random noise to the audio signal before quantization.
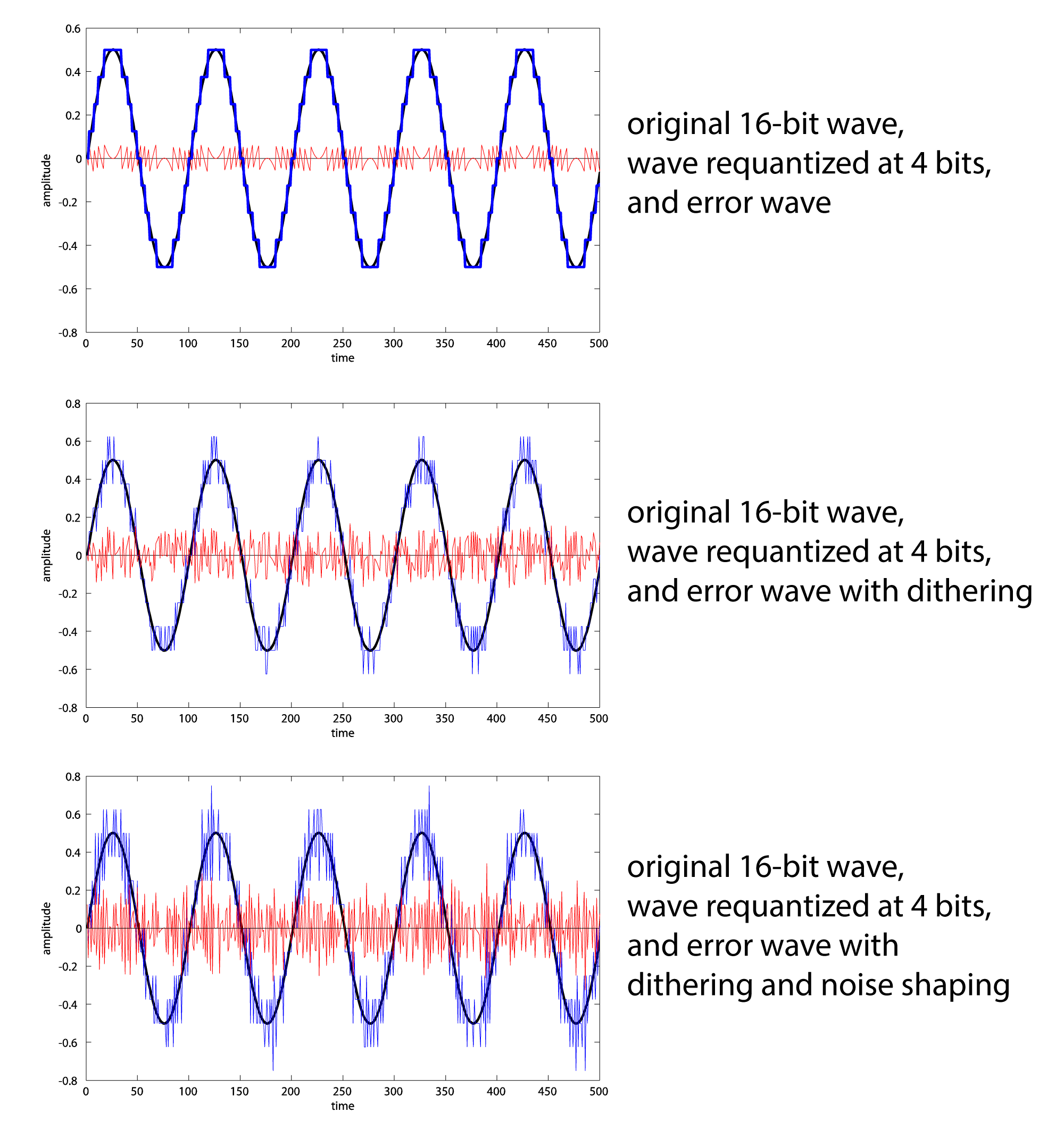
Photo courtesy of: https://digitalsoundandmusic.com/
How It Works
Noise Addition: A low-level random noise signal is added to the original audio signal before it is quantized.
Quantization: The combined signal (original audio + dither noise) is then quantized to the nearest available digital value.
The addition of dither noise randomizes the quantization errors, making the resulting noise more uniform and less perceptible. This technique is particularly useful when working with low bit depths where quantization noise is more prominent.
Least Significant Bit (LSB)
The least significant bit (LSB) in a digital audio sample represents the smallest possible change in amplitude. In digital audio, where the signal is represented by binary digits (0s and 1s), the LSB is crucial for maintaining audio detail, especially at low signal levels.
To understand the role of the LSB and dithering, consider this analogy: digital audio can be likened to a light switch being turned on or off. When the audio signal fluctuates between these binary states (0 and 1), there can be noticeable clicks or pops as the signal rapidly changes. By adding a small amount of dither noise, the signal smooths out these transitions, preventing abrupt changes and ensuring a continuous, more natural sound.
Dithering preserves the integrity of the LSB, ensuring that even tiny variations in the audio signal are captured more accurately, enhancing the overall audio quality.
Why Use Dither?
Noise Shaping: Dithering ensures that the quantization noise is spread out over a wide range of frequencies rather than being concentrated at specific frequencies, which can be more noticeable and unpleasant.
Low-Level Signal Preservation: By adding dither, subtle details and low-level signals are better preserved, resulting in a more natural and accurate reproduction of the original audio.
In modern digital workstations, dithering is often automatic, so beginners don't need to worry about it much. However, in mastering and high-level mixing, dithering becomes crucial. As the dynamic range of music increases (making the quiet parts quieter), there is more potential for quantization error. Audio professionals have the ability to choose different types of dither such as :
Triangular Dithering: Adds triangular-shaped noise, suitable for general use.
Rectangular Dithering: Adds rectangular-shaped noise, effective for digital-to-analog conversion.
Noise Shaping: Uses shaped noise to minimize audibility, ideal for high-resolution audio.
Nyquist Theorem:
The Nyquist theorem states that to accurately reproduce a signal, the sample rate must be at least twice the highest frequency present in that signal. For human hearing, which typically ranges up to 20 kHz, this means a minimum sample rate of 40 kHz is necessary to capture all audible frequencies. This principle underpins the standard 44.1 kHz sample rate used in CDs, which was chosen to avoid aliasing—a form of distortion that occurs when a signal is undersampled, leading to incorrect frequency representation. Aliasing results in high-frequency components of the signal being misrepresented as lower frequencies, creating an audible distortion.
To prevent aliasing, the Nyquist theorem suggests using a sample rate just above double the highest frequency, but in practice, engineers often employ a slight buffer, leading to the choice of 44.1 kHz rather than exactly 40 kHz for CD audio. Oversampling—using a sample rate significantly higher than the Nyquist rate—can help further reduce the effects of quantization noise and make filtering easier, resulting in cleaner and more accurate audio reproduction. While oversampling doesn't increase the actual frequency content beyond the original signal's range, it can help improve the fidelity of the digital representation by minimizing potential artifacts.

Understanding these fundamental concepts—sampling, sample rate, bit depth, and the Nyquist theorem—is essential for anyone working with digital audio. These parameters determine the quality and fidelity of the digital audio recording, influencing both the capture and playback of sound.
Storage Size
The storage size of digital audio files depends directly on the sample rate and bit depth. Higher sample rates, which indicate the number of samples taken per second, result in more data being captured per second of audio, thus increasing the file size. Similarly, higher bit depths, which define the number of possible amplitude values each sample can have, also lead to larger file sizes because each sample requires more bits to store. For instance, audio recorded at 96 kHz and 24-bit depth will consume significantly more storage than audio recorded at 44.1 kHz and 16-bit depth. The increased data from higher sample rates and bit depths provides better audio quality but demands more storage space, making it crucial to balance quality and file size based on the intended use.

Lossless vs. Lossy Formats
Lossless:
Lossless audio formats retain all the original audio data, ensuring no loss of quality. These formats are essential in the recording process, where fidelity and editing flexibility are paramount. In professional settings, recording in lossless formats like WAV or AIFF ensures the highest quality capture, enabling detailed editing and mixing. Lossless compression reduces file size without affecting audio quality, making formats like FLAC and ALAC popular among audiophiles and for archival purposes.
Lossy:
Lossy audio formats compress audio data by discarding some information, which reduces file size but also impacts quality. The primary goal of lossy compression is to reduce the amount of data needed to represent the audio, making it more efficient for storage and transmission. This process involves several techniques:
1. Perceptual Coding: This technique exploits the limitations of human hearing by removing audio information that is less likely to be perceived by the listener. For example, very high and very low frequencies, which are less audible, can be discarded.
2. Quantization: During quantization, the audio signal's amplitude is rounded to the nearest value within a limited set of levels. This reduces the precision of the audio data but significantly decreases the file size.
3. Transform Coding: This method converts the audio signal from the time domain to the frequency domain using mathematical transformations (such as the Discrete Cosine Transform). It then applies compression in the frequency domain, which is more efficient.
These techniques combine to create formats like MP3, AAC, and OGG, which offer a good balance between audio quality and file size. Lossy formats are ideal for streaming and downloading, where bandwidth and storage constraints exist.
Lossy Formats:
MP3: The most widely used lossy format, MP3 compresses audio data to reduce file size while maintaining acceptable quality. Ideal for everyday listening and streaming.
AAC: Preferred by Apple, AAC offers better quality at similar bitrates compared to MP3. Commonly used in Apple’s ecosystem and various streaming services.
OGG: An open-source alternative to MP3 and AAC, OGG is used in gaming and streaming applications where licensing fees for proprietary formats are undesirable.
Lossless Formats:
WAV: An uncompressed format that delivers high-quality audio but results in large file sizes. WAV is the standard for professional audio recording and editing.
· BWAV: Broadcast WAV (BWAV) is an extension of the standard WAV format that includes additional metadata. This metadata can contain information such as timestamps, track descriptions, and other data useful in professional audio environments, particularly in broadcasting and film production. BWAV files offer the same high-quality audio as standard WAV files but with added functionality for more detailed audio project management.
AIFF: Similar to WAV, AIFF is an uncompressed format commonly used on Apple systems for high-quality audio recording and editing.
FLAC: A compressed lossless format that maintains original audio quality while reducing file size compared to WAV. FLAC is popular among audiophiles and for archival purposes but is not typically used for recording.
Choosing the Right Format: Recording vs. Distribution
Understanding the appropriate audio formats for recording and distribution is crucial for achieving the best audio quality and efficient file management. Here’s an expanded look at the different needs and suitable formats for each process.
Recording
Use Lossless Formats for High-Quality Capture:
WAV (Waveform Audio File Format): WAV files are uncompressed and maintain the highest possible audio quality. This format is widely used in professional recording studios due to its high fidelity and compatibility with virtually all audio editing software.
AIFF (Audio Interchange File Format): Similar to WAV, AIFF is an uncompressed format developed by Apple. It offers excellent audio quality and is commonly used in Apple-based recording environments.
BWAV (Broadcast Wave Format): An extension of the standard WAV format, BWAV includes additional metadata such as timestamps and track descriptions, making it particularly useful in broadcasting and film production.
Why Lossless Formats?
High Fidelity: Lossless formats retain all the original audio data, ensuring no loss of quality. This is essential for capturing the full detail and nuance of the performance.
Editing Flexibility: The high resolution and dynamic range provided by lossless formats allow for more precise editing and mixing. Audio engineers can manipulate the sound extensively without introducing artifacts or degradation.
Archival Quality: Lossless files serve as the best master copies, preserving the original recording for future use and ensuring that the highest quality is available for any subsequent editing or processing.
Distribution
Use Lossy Formats for Efficient Distribution:
MP3 (MPEG Audio Layer III): MP3 is one of the most widely used lossy formats. It compresses audio data to reduce file size significantly, making it ideal for streaming and downloading. Despite the compression, MP3 maintains a reasonable balance between file size and audio quality.
AAC (Advanced Audio Coding): AAC offers better audio quality than MP3 at similar bitrates and is preferred for streaming services and digital music platforms. It is the standard format for Apple’s iTunes and various other streaming services.
Why Lossy Formats?
File Size Reduction: Lossy formats significantly reduce file size by compressing audio data, which is crucial for efficient distribution, especially over the internet. Smaller files are quicker to download and stream, reducing bandwidth usage and storage requirements.
Broad Compatibility: Most consumer devices and media players support lossy formats like MP3 and AAC, ensuring that your audio can reach a wide audience without compatibility issues.
Quality vs. Convenience: While lossy formats do sacrifice some audio quality due to compression, modern codecs are designed to minimize perceptual loss, ensuring that the degradation is often imperceptible to the average listener. This makes lossy formats a practical choice for most distribution needs where file size and accessibility are more critical than absolute fidelity.
Codec Comparison
In digital audio, various codecs serve different purposes, balancing compression efficiency, audio quality, compatibility, and use cases. Here, we compare some of the most popular codecs: MP3, AAC, FLAC, ALAC, and OGG.
MP3 (MPEG Audio Layer III)
Compression Efficiency: MP3 uses lossy compression, significantly reducing file size by discarding audio information that is less perceivable to human ears. It achieves good compression ratios, making it suitable for internet streaming and storage on portable devices.
Quality: While MP3 provides reasonable audio quality at higher bitrates (e.g., 192 kbps and above), it does sacrifice some fidelity, especially at lower bitrates.
Compatibility: MP3 is one of the most widely supported audio formats across various devices and platforms, including computers, smartphones, and media players.
Use Cases: Ideal for music streaming, portable media players, and situations where storage space is a concern.
AAC (Advanced Audio Coding)
Compression Efficiency: AAC is also a lossy codec but offers better compression efficiency than MP3. It provides higher quality at similar bitrates, making it more efficient.
Quality: AAC delivers superior audio quality compared to MP3 at equivalent bitrates. It maintains better fidelity and is less prone to artifacts.
Compatibility: Widely supported by modern devices and platforms, AAC is the preferred format for Apple's iTunes and many streaming services like YouTube and Apple Music.
Use Cases: Commonly used for streaming services, digital downloads, and mobile applications where quality and efficiency are paramount.
FLAC (Free Lossless Audio Codec)
Compression Efficiency: FLAC is a lossless codec, meaning it compresses audio without any loss in quality. It reduces file size to about 50-70% of the original, retaining all audio details.
Quality: As a lossless format, FLAC provides identical audio quality to the original recording, making it ideal for high-fidelity audio.
Compatibility: Increasingly supported by a wide range of devices and platforms, including high-end audio equipment, media players, and software applications.
Use Cases: Best for archiving, high-fidelity audio playback, and situations where audio quality is critical, such as professional audio production.
ALAC (Apple Lossless Audio Codec)
Compression Efficiency: Similar to FLAC, ALAC is a lossless codec that compresses audio data without quality loss, achieving compression ratios comparable to FLAC.
Quality: Provides the same high-quality, lossless audio experience as FLAC.
Compatibility: Primarily supported by Apple devices and software, such as iTunes and iOS devices, but also playable on other platforms with compatible software.
Use Cases: Preferred for users within the Apple ecosystem who need high-fidelity audio, such as for music libraries and professional audio work.
OGG (Ogg Vorbis)
Compression Efficiency: OGG is a lossy codec designed to provide high-quality audio at lower bitrates compared to MP3. It is open-source and free from licensing fees, making it a popular choice for developers.
Quality: Delivers better audio quality than MP3 at comparable bitrates, and is often used in applications where audio quality is important but bandwidth or storage is limited.
Compatibility: Supported by many media players and software applications, though not as universally compatible as MP3 or AAC.
Use Cases: Commonly used in gaming, streaming, and open-source applications where licensing costs are a concern.

By understanding the strengths and weaknesses of each codec, you can select the best format for your specific needs, whether it’s for high-quality audio production, efficient streaming, or versatile playback compatibility.
Common Myths and Misconceptions About Audio Formats
Myth 1: Higher Bitrate Always Means Better Quality
While higher bitrates can improve audio quality by allowing more data to be processed per second, this is not the sole factor determining audio quality. The source material's quality and the encoding process are equally crucial. A poorly recorded audio at a high bitrate will not sound better than a well-recorded audio at a lower bitrate. High bitrates are beneficial for maintaining quality during multiple editing stages, but they do not guarantee superior sound on their own (Pro Audio Files) (Unison).
Myth 2: Lossless Formats Are Always Necessary
Lossless formats like WAV, AIFF, and FLAC preserve all the original audio data, making them ideal for recording, editing, and archiving high-quality audio. However, for everyday listening and distribution, lossy formats such as MP3 and AAC often suffice. Modern lossy codecs can compress audio efficiently while maintaining a quality that is perceptually indistinguishable from the original for most listeners. This makes lossy formats a practical choice for saving storage space and bandwidth without compromising too much on quality (Unison) (Pro Audio Files).
Myth 3: MP3 Is Outdated and Unusable
Despite the advent of newer formats, MP3 remains widely supported and offers a good balance between file size and audio quality. Advances in MP3 encoding have significantly improved its efficiency and sound quality. While formats like AAC provide better quality at similar bitrates, MP3's ubiquity and compatibility across devices ensure it remains a viable option for both casual listeners and professionals (Pro Audio Files).
By understanding these myths and the realities behind them, you can make more informed decisions about choosing the right audio formats for your needs, whether for high-fidelity recording, efficient distribution, or everyday listening.
Conclusion
Understanding digital audio formats is essential for anyone involved in creating or consuming audio content. By choosing the right formats for recording and distribution, you can ensure the best possible audio experience for your audience. Experiment with different formats to find the perfect balance of quality and convenience for your needs.